Ahead of the annual International Conference for High Performance Computing, Networking, Storage, and Analysis, better known as the SC, Nvidia announced its new version of CUDA, CUDA 6. While most recent updates to CUDA had quite a few new features, the CUDA 6 will mostly focus on a few elements that might be quite important.
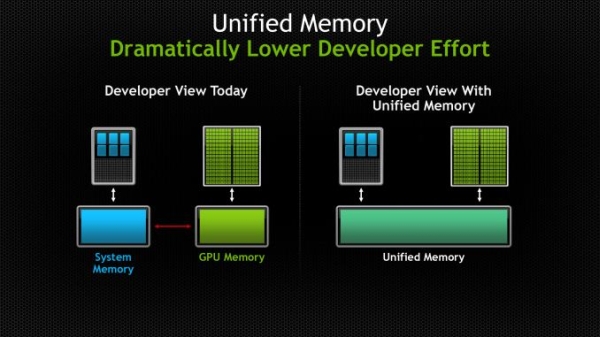
The bigest news is definitely the unified memory support wihtin CUDA. While CUDA 4 already had unified virtual addressing support which allowed x86 and GPU memory to be addressed together in a single space, it only simplified memory management and did not solve some issues that such a solution had and still required memory copying that will allow GPU to work with it.
With CUDA 6, Nvidia moved towards removing issues like memory copying by implementing a unified memory system on top of the existing memory pool structure. Basically, unified memory allows programmers to access any resource or addres within the legal address space, regardless of the place where it is in and actually use it without the need to copy it over.
While it does not resolve technical limitations that require memory copying, like limited bandwidth and latency of the PCIe, it moves memory management to CUDA rather than other toolkit, thus simply making the life of the programmer much easier.
Basically it does not solve any performance issues but rather simplifes CUDA programming. This move is made in order to make CUDA programming more accessible to wider audiences.
Nvidia did not shed any light regarding performance impact at this time, and while manual memory management is still present, CUDA unified memory will definitely have some kind of performance penalty.
Nvidia also revealed that while we are currently seeing software implementation of unified memory with CUDA 6, Maxwell will most likely have some sort of hardware functionality for implementing unified memory thus removing any performance penalties and most likely doing it much better than software solution with CUDA 6.
Via Anandtech.com.